



Implementando Dimensiones y Tablas de Hechos
La
implementación de un data warehouse significa crear la base de datos data
warehouse (DW) y los objetos de base de datos. Los objetos de base de datos
principales, son las dimensiones y las tablas de hechos. Para acelerar los
procesos de extracción-transformación-carga (ETL), puede tener objetos
adicionales en su DW, incluyendo secuencias, procedimientos almacenados, y
tablas staging. Después de crear los objetos, debería probarlos cargando los
datos de prueba.
Creando una Base de Datos Data Warehouse
Debe considerar un par de
ajustes cuando crea una base de datos Data Warehouse. Un DW contiene una copia
transformada de los datos de línea de negocio (LOB). La carga de datos a la DW
se hace ocasionalmente, sobre un calendario, típicamente en un job nocturno.
Los datos DW no están en línea, no son datos en tiempo real. No necesita
realizar copias de seguridad del registro de transacciones para su data
warehouse, como lo haría en una base de datos LOB. Por lo tanto, el modelo de
recuperación para su data warehouse debería ser la Simple.
SQL Server soporta tres modelos de recuperación:
·
El Modelo de Recuperación Full.
·
El Modelo de Recuperación Bulk
Logged.
·
El Modelo de Recuperación Simple.
El modelo de recuperación Simple es útil para bases de datos de
desarrollo, de prueba, y mayormente de lectura. Porque en un data warehouse se
utiliza principalmente datos en modo de sólo lectura, el modelo Simple es el
más adecuado para un data warehouse. Si utiliza los modelos de recuperación
Full o Bulk Logged, debe hacer una copia de seguridad del registro
regularmente, porque de otra manera el registro crecerá constantemente con cada
nueva carga de datos.
Los datos y los archivos de
registro de la base de datos SQL Server pueden crecer y reducirse
automáticamente. Sin embargo, el crecimiento sucede en el tiempo más
inconveniente, cuando se cargan nuevos datos, interfiriendo con su carga, y
haciendo más lenta la carga. Numerosas operaciones de pequeños crecimientos
pueden fragmentar sus datos. Las reducciones automáticas pueden fragmentar los
datos aún más. Para las consultas que leen muchos datos, realizando grandes
exploraciones de tablas, querrá eliminar la fragmentación tanto como sea
posible. Por lo tanto, debe evitar la autoreducción y el autocrecimiento.
Asegúrese de que la opción de base de datos AutoShrink este desactivada. Aunque
no se puede evitar el crecimiento de la base de datos, debe reservar espacio
suficiente para sus datos y archivos de registro inicialmente, para evitar el
autocrecimiento.
Puede calcular los
requerimientos de espacio con bastante facilidad. Un data warehouse contiene
datos para varios años, por lo general para 5 o 10 años. Cargar datos de prueba
para un período limitado, por ejemplo un año (o un mes, si se trata de grandes
bases de datos de origen). Entonces compruebe el tamaño de su archivo de base
de datos y extrapole el tamaño para los 5 o 10 años completos de valores de
datos. Además, se debería añadir al menos un 25 por ciento para espacio libre
extra en sus archivos de datos. Este espacio adicional libre le permite
reconstruir o volver a crear índices sin fragmentación.
Aunque el registro de
transacciones no crece en el modelo de recuperación Simple, todavía debe
ajustarlo para que sea lo suficientemente extenso para acomodar la transacción
más grande. Normalmente las sentencias del Lenguaje de Modificación de Datos
(DML), que incluyen INSERT, DELETE, UPDATE, y MERGE, son siempre completamente registradas, incluso en el modelo Simple.
Debe probar la ejecución de estas sentencias y estimar un tamaño apropiado para
su registro.
En su data warehouse,
extensas tablas de hechos típicamente ocupan la mayor parte del espacio. Puede
optimizar consultas y gestionar extensas tablas de hechos a través del particionamiento. El particionamiento de
tablas tiene ventajas de gestión y proporciona beneficios en el rendimiento.
Las consultas frecuentemente sólo tocan subconjuntos de particiones y SQL
Server puede eliminar eficientemente otras particiones tempranamente, en el
proceso de ejecución de la consulta.
Una base de datos puede
tener varios archivos de datos, agrupados en varios filegroups. No existe una buena práctica simple, como el conocer
cuántos filegroups debe crear para su data warehouse. Sin embargo, para la
mayoría de los escenarios DW, tener un filegroup para cada partición es lo más
adecuado. Para el número de archivos en un filegroup, debe considerar su
almacenamiento en disco. Por lo general, debe crear un archivo por cada disco
físico.
Cargar datos desde sistemas
de origen es a menudo muy complejo. Para mitigar la complejidad, puede
implementar tablas staging en su DW. Incluso puede implementar tablas staging y
otros objetos en una base de datos separada. Utilice tablas staging para almacenar temporalmente datos de origen, antes
de limpiarlos o fusionarlos con datos de otros orígenes. Además, las tablas
staging también sirven como una capa intermedia entre las tablas DW y las
tablas de origen. Si algo cambia en el origen, por ejemplo, si una base de
datos de origen es actualizada, tiene que cambiar sólo la consulta que lee los
datos de origen y cargarlas a las tablas staging. Después de eso, el proceso
regular ETL debería funcionar tal como lo hizo antes del cambio en el sistema
de origen. La parte de un DW conteniendo tablas staging, es llamada Area
Staging de Datos (DSA).
Las tablas staging nunca
son expuestas a los usuarios finales. Si son parte de su DW, puede almacenarlos
en un esquema diferente, que el de las tablas regulares del esquema Estrella.
Por almacenar tablas staging en un esquema diferente, puede dar permisos a los
usuarios finales sobre las tablas DW regulares, asignar estos permisos para el
esquema apropiado solamente, lo que simplifica la gestión. En una data
warehouse típica, dos esquemas son suficientes: uno para las tablas regulares
DW, y otro para las tablas staging. Puede almacenar tablas DW regulares en el
esquema dbo y, si es necesario, crear
un esquema separado para tablas staging.
Implementando Dimensiones
La implementación de una
dimensión implica la creación de una tabla que contiene todas las columnas
necesarias. En adición a las llaves del negocio, debe agregar una llave
sustituta en todas las dimensiones que necesita gestionar una Dimensión de
Variación Lenta (SCD) Tipo 2. También debe agregar una columna que marque la
fila actual o dos columnas de fecha que marquen el período de validez de una
fila, cuando implemente una gestión SCD Tipo 2 para una dimensión.
Puede utilizar enteros
secuenciales simples para llaves sustitutas. SQL Server puede autonumerarlos.
Puede utilizar la propiedad IDENTITY para generar números secuenciales. Ya
debería estar familiarizado con esta propiedad. En SQL Server 2014, también
puede utilizar secuencias para los identificadores.
Una secuencia es un objeto
independiente de la tabla, definido por el usuario (y, por tanto, ligado al esquema).
SQL Server utiliza secuencias, para generar una secuencia de valores numéricos
de acuerdo a su especificación. Puede generar secuencias en orden ascendente o
descendente, utilizando un intervalo definido de valores posibles. Incluso
puede generar secuencias con ciclos (repetitivos). Como se ha mencionado, las
secuencias son objetos independientes, no asociados con tablas. Se puede
controlar la relación entre las secuencias y las tablas en su aplicación ETL.
Con las secuencias, puede coordinar los valores llave a través de múltiples
tablas.
Además de las columnas
regulares, también puede agregar columnas
calculadas. Una columna calculada es una columna virtual en una tabla. El
valor de la columna está determinado por una expresión. Al definir columnas
calculadas en sus tablas, puede simplificar las consultas. Las columnas
calculadas pueden también ayudar con el rendimiento. Puede persistir e índexar
una columna calculada, siempre y cuando se cumplan los siguientes
prerrequisitos:
·
Requisitos de Propiedad
·
Requisitos de Determinismo
·
Requisitos de Precisión
·
Requisitos de Tipo de datos
·
Requisitos de opción SET
Implementando Tablas de Hechos
Después de implementar las
dimensiones, es necesario implementar las tablas de hechos en su data
warehouse. Siempre debe implementar las tablas de hechos después de implementar sus dimensiones. Una tabla de hechos está en
el lado "muchos" de una relación con una dimensión, asi el lado padre
debe existir si desea crear una restricción de llave foránea.
Debe particionar una tabla
de hechos grande para un mantenimiento más fácil y un mejor rendimiento.
Las columnas en una tabla
de hechos incluyen las llaves foráneas y las medidas. Las dimensiones en su
base de datos definen las llaves foráneas. Todas las llaves foráneas juntas
suelen identificar de forma única cada fila de una tabla de hechos. Si ellas
identifican de forma unica cada fila, entonces puede utilizarlas como una llave
compuesta. También puede añadir una llave primaria sustituta adicional, que
también podría ser una llave heredada de una tabla del sistema LOB. Por
ejemplo, si inicia la construcción de su tabla de hechos Ventas del DW, de una
tabla de Detalle de Pedido de Ventas LOB, puede utilizar la llave de esta
tabla, para la tabla de hechos de Ventas del LOB también.
En producción, puede eliminar las restricciones de llave foránea para
lograr un mejor rendimiento de carga. Si las restricciones de llaves foráneas
están presentes, SQL Server tiene que comprobarlas durante la carga. Sin
embargo, recomendamos que conserve las restricciones de llaves foráneas durante
el desarrollo y fases de prueba. Es más fácil crear diagramas de base de datos
si tiene las llaves foráneas definidas. Además, durante las pruebas, obtendrá
errores si las restricciones son violadas. Los errores le informan que hay algo
mal con sus datos; cuando ocurre una violación de llave foránea, es muy
probable que la fila padre de una dimensión, este faltando para una o más filas
en la tabla de hechos. Estos tipos de errores nos dan información acerca de la
calidad de los datos con los que está tratando.
Si decide eliminar las
llaves foráneas en producción, debe crear su proceso ETL para que sea más
flexible cuando se produzcan errores en una llave foránea. En su proceso ETL,
debe agregar una fila a una dimensión cuando una llave desconocida aparezca en
una tabla de hechos. Una fila en una dimensión agregada durante la carga de la
tabla de hechos, es llamado un miembro
inferido. Excepto para los valores de llave, todos los otros valores de
columna para una fila de miembro inferido en una dimensión, son desconocidos en
el tiempo de carga de la tabla de hechos, y debería configurarlos a NULL. Esto
significa que las columnas de dimensión (excepto llaves) deberían permitir
NULLs. El asistente SCD del SQL Server Integration Services (SSIS) le ayuda a
manejar los miembros inferidos en tiempos de carga de dimensión. El problema de
miembros inferidos, es también conocido como el problema de dimensiones de llegada tardía.
Al igual que en
las dimensiones, las tablas de hechos también pueden contener columnas
calculadas. Puede crear muchos cálculos anticipadamente y así simplificar las
consultas. Y, por supuesto, también como en las dimensiones, las tablas de
hechos pueden tener columnas de linaje añadidas si los necesita.
Ejercicio: Implementando Dimensiones y Tablas de Hechos
En esta
práctica, implementará un data warehouse. Utilizará la base de datos de ejemplo
AdventureWorksDW2014 como origen de datos. No creará un área staging de datos
explícita; usará la base de datos de ejemplo AdventureWorksDW2014 como su área
staging de datos.
Crear una Base de Datos Data Warehouse y una Secuencia
Creará una base de datos
SQL Server para su data warehouse.
1.
Inicie el SSMS y conéctese a la instancia de SQL Server. Abra una nueva
ventana de consulta, dando clic al botón New Query.
2.
Desde el contexto de la base de datos master, cree una nueva base de
datos llamada SSISDW. Antes de crear
la base de datos, compruebe si existe, y elimínela de ser necesario. Siempre
verifique si existe un objeto y elimínelo de ser necesario. La base de datos
debe tener las siguientes propiedades:
· Se debe tener un solo archivo de datos y un archivo de registro en la
carpeta SSIS. Puede crear esta carpeta en cualquier unidad que desee.
· El archivo de datos debe tener un tamaño inicial de 300 MB y debe tener
activado el crecimiento automático de bloques de 10MB.
· El tamaño del archivo de registro debe ser de 50 MB, con un 10 por ciento
de crecimiento automático.
3.
Después de crear la base de datos, cambiar el modelo de recuperación a
Simple. Aquí está el código de creación de base de datos completo.
USE master;
IF DB_ID('SSISDW') IS NOT NULL
DROP DATABASE SSISDW;
GO
CREATE DATABASE SSISDW
ON PRIMARY
(NAME = N'SSISDW', FILENAME = N'C:\SSIS\SSISDW.mdf',
SIZE = 307200KB , FILEGROWTH = 10240KB )
LOG ON
(NAME = N'SSISDW_log', FILENAME = N'C:\SSIS\SSISDW_log.ldf',
SIZE = 51200KB , FILEGROWTH = 10%);
GO
ALTER DATABASE SSISDW SET RECOVERY SIMPLE WITH NO_WAIT;
GO
4.
En su nuevo data warehouse, crear un objeto de secuencia. Nómbrelo como SeqCustomerDwKey. Iniciar numeración
con 1, y usar un incremento de 1. Para otras opciones de secuencia, use los
valores predeterminados de SQL Server. Puede utilizar el código siguiente.
USE SSISDW;
GO
IF OBJECT_ID('dbo.SeqCustomerDwKey','SO') IS NOT NULL
DROP SEQUENCE dbo.SeqCustomerDwKey;
GO
CREATE SEQUENCE dbo.SeqCustomerDwKey AS INT
START WITH 1
INCREMENT BY 1;
GO
Crear Dimensiones
Creará la dimensión Customers. En la base de datos
AdventureWorksDW2014, la dimensión DimCustomer,
servirá de origen para su dimensión Customers,
que es parcialmente Snowflaked. Cuenta con una tabla de búsqueda de nivel-uno,
llamada DimGeography. Desnormalizará
completamente esta dimensión. Además, agregará las columnas necesarias para
soportar una dimensión SCD Tipo 2 y un par de columnas calculadas. Además de la
dimensión Customers, se creará las
dimensiones Products y Dates.
1.
Crear la dimensión Customers. El
origen de esta dimensión es la dimensión DimCustomer
de la base de datos de ejemplo AdventureWorksDW2014. Agregar una columna de
llave sustituta llamada CustomerDwKey,
y crear una restricción de llave primaria sobre esta columna. Utilice la tabla siguiente
para la información necesaria para definir las columnas de la tabla y para
poblar la tabla.
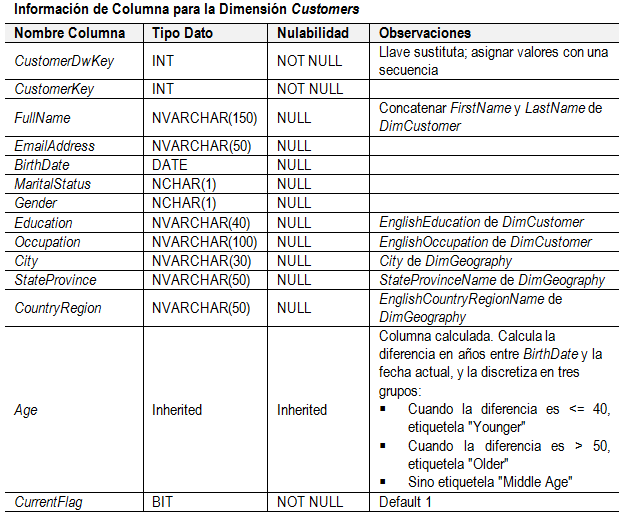
2.
Su código para crear la dimensión Customers
debe ser similar al código en el listado siguiente.
CREATE TABLE dbo.Customers
(
CustomerDwKey INT NOT NULL,
CustomerKey INT NOT NULL,
FullName NVARCHAR(150) NULL,
EmailAddress NVARCHAR(50) NULL,
BirthDate DATE NULL,
MaritalStatus NCHAR(1) NULL,
Gender NCHAR(1) NULL,
Education NVARCHAR(40) NULL,
Occupation NVARCHAR(100) NULL,
City NVARCHAR(30) NULL,
StateProvince NVARCHAR(50) NULL,
CountryRegion NVARCHAR(50) NULL,
Age AS
CASE
WHEN BirthDate IS NULL THEN NULL
WHEN DATEDIFF(yy,BirthDate,CURRENT_TIMESTAMP)
> 50
THEN 'Older'
WHEN DATEDIFF(yy,BirthDate,CURRENT_TIMESTAMP)
> 40
THEN 'Middle Age'
ELSE 'Younger'
END,
CurrentFlag BIT NOT NULL DEFAULT 1,
CONSTRAINT PK_Customers PRIMARY KEY (CustomerDwKey)
);
GO
3.
Crear la dimensión Products.
El origen para esta dimensión es la dimensión DimProducts de la base de datos de ejemplo AdventureWorksDW2014.
Utilice la tabla siguiente para la información que necesita para crear y poblar
esta tabla.

El código para la creación de la dimensión Products
debe ser similar al código en el siguiente listado.
CREATE TABLE dbo.Products
(
ProductKey INT NOT NULL,
ProductName NVARCHAR(50) NULL,
Color NVARCHAR(15) NULL,
Size NVARCHAR(50) NULL,
SubcategoryName
NVARCHAR(50) NULL,
CategoryName NVARCHAR(50) NULL,
CONSTRAINT PK_Products PRIMARY KEY (ProductKey)
);
GO
4.
Crear la dimensión Dates. El
origen para esta dimensión es la dimensión DimDate
de la base de datos de ejemplo AdventureWorksDW2014. Utilice la tabla siguiente
para obtener la información que necesita para crear y poblar esta tabla.

El código para la creación de la dimensión Dates
debería ser similar al código en el siguiente listado.
CREATE TABLE dbo.Dates
(
DateKey INT NOT NULL,
FullDate DATE NOT NULL,
MonthNumberName
NVARCHAR(15) NULL,
CalendarQuarter
TINYINT
NULL,
CalendarYear SMALLINT NULL,
CONSTRAINT PK_Dates PRIMARY KEY (DateKey)
);
GO
Crear una Tabla de Hechos
En este ejemplo
simplificado de un data warehouse real, creará una sola tabla de hechos. En
este ejemplo, no se puede utilizar todas las llaves foráneas juntas como una
llave primaria compuesta, porque el origen de esta tabla, la tabla FactInternatSales de la base de datos
AdventureWorksDW2014 tiene una granularidad inferior a la tabla de hechos que
está creando, y la llave primaria podría ser duplicada. Podría utilizar las
columnas SalesOrderNumber y SalesOrderLineNumber como la llave
primaria, como en una tabla de origen; sin embargo, con el fin de mostrar cómo
se puede autonumerar una columna con la propiedad IDENTITY, en este ejercicio
tiene que añadir su propia columna entera con esta propiedad. Esta será su
llave sustituta.
1.
Crear la tabla de hechos InternetSales.
El origen para esta tabla de hechos es la tabla de hechos FactInternetSales de la base de datos de ejemplo,
AdventureWorksDW2014. Añadir las llaves foráneas de las tres dimensiones
creadas anteriormente. Añadir una columna entera por utilizar la propiedad
IDENTITY, y usarla como la llave primaria. Utilice la tabla siguiente para la
información necesaria para definir las columnas de la tabla.

El código para crear la tabla de hecho InternetSales
debería ser similar al código en el listado siguiente.
CREATE TABLE dbo.InternetSales
(
InternetSalesKey
INT NOT NULL IDENTITY(1,1),
CustomerDwKey INT NOT NULL,
ProductKey INT NOT NULL,
DateKey INT NOT NULL,
OrderQuantity SMALLINT NOT NULL DEFAULT 0,
SalesAmount MONEY NOT NULL DEFAULT 0,
UnitPrice MONEY NOT NULL DEFAULT 0,
DiscountAmount FLOAT NOT NULL DEFAULT 0,
CONSTRAINT PK_InternetSales
PRIMARY KEY (InternetSalesKey)
);
GO
2.
Alterar la tabla de hechos InternetSales,
para añadir restricciones de llave foránea, para las relaciones con todas las
tres dimensiones. El código se muestra en el listado siguiente.
ALTER TABLE dbo.InternetSales ADD CONSTRAINT
FK_InternetSales_Customers
FOREIGN KEY(CustomerDwKey)
REFERENCES dbo.Customers (CustomerDwKey);
ALTER TABLE dbo.InternetSales ADD CONSTRAINT
FK_InternetSales_Products
FOREIGN KEY(ProductKey)
REFERENCES dbo.Products (ProductKey);
ALTER TABLE dbo.InternetSales ADD CONSTRAINT
FK_InternetSales_Dates
FOREIGN KEY(DateKey)
REFERENCES dbo.Dates (DateKey);
GO
3.
Crear un diagrama de base de datos, como se muestra en la figura siguiente.
Nómbrelo como InternetSalesDW y
guárdelo.
4. Esto termina la
implementación de la Dimensiones y Tabla de Hechos.
Cargando Datos y usando Compresión de Datos e Indices Columnstore
En este
ejercicio, cargará los datos al data warehouse que ha creado anteriormente.
Utilizará la base de datos de ejemplo AdventureWorksDW2014 como origen de
datos. Después de cargar los datos, aplicará la compresión de datos y creará un
índice columnstore.
Cargar el Data Warehouse
Primero cargará los datos
en su data warehouse.
1.
Si cerró el SSMS, inícielo y conéctese a la instancia de SQL Server.
Abra una nueva ventana de consulta haciendo clic en el botón New Query.
2.
Conéctese a la base de datos SSISDW. Cargue la dimensión Customers utilizando información de la
tabla siguiente.

La consulta de carga se muestra en el siguiente
código.
INSERT INTO dbo.Customers
(CustomerDwKey, CustomerKey, FullName,
EmailAddress, Birthdate, MaritalStatus,
Gender, Education, Occupation,
City, StateProvince, CountryRegion)
SELECT
NEXT VALUE FOR dbo.SeqCustomerDwKey AS CustomerDwKey,
C.CustomerKey,
COALESCE(C.FirstName+' ','') + COALESCE(C.LastName,'') AS FullName,
C.EmailAddress, C.BirthDate, C.MaritalStatus,
C.Gender, C.EnglishEducation, C.EnglishOccupation,
G.City, G.StateProvinceName, G.EnglishCountryRegionName
FROM AdventureWorksDW2014.dbo.DimCustomer AS C
INNER JOIN AdventureWorksDW2014.dbo.DimGeography AS G
ON C.GeographyKey = G.GeographyKey;
GO
3.
Cargue la dimensión Products
mediante el uso de la información de la tabla siguiente.

La consulta de carga se muestra en el siguiente
código.
INSERT INTO dbo.Products
(ProductKey, ProductName, Color,
Size, SubcategoryName, CategoryName)
SELECT P.ProductKey, P.EnglishProductName, P.Color,
P.Size, S.EnglishProductSubcategoryName, C.EnglishProductCategoryName
FROM AdventureWorksDW2014.dbo.DimProduct AS P
INNER JOIN AdventureWorksDW2014.dbo.DimProductSubcategory
AS S
ON P.ProductSubcategoryKey =
S.ProductSubcategoryKey
INNER JOIN AdventureWorksDW2014.dbo.DimProductCategory AS C
ON S.ProductCategoryKey = C.ProductCategoryKey;
GO
4.
Cargue la dimensión Dates
utilizando la información de la tabla siguiente.

La consulta de carga se muestra en el siguiente
código.
INSERT INTO dbo.Dates
(DateKey, FullDate, MonthNumberName,
CalendarQuarter, CalendarYear)
SELECT DateKey, FullDateAlternateKey,
FORMAT(MonthNumberOfYear,'00 ') + EnglishMonthName,
CalendarQuarter, CalendarYear
FROM AdventureWorksDW2014.dbo.DimDate;
GO
5.
Cargue la tabla de hechos InternetSales
utilizando la información de la tabla siguiente.

La consulta de carga se muestra en el siguiente
código.
INSERT INTO dbo.InternetSales
(CustomerDwKey, ProductKey, DateKey,
OrderQuantity, SalesAmount,
UnitPrice, DiscountAmount)
SELECT C.CustomerDwKey,
FIS.ProductKey, FIS.OrderDateKey,
FIS.OrderQuantity, FIS.SalesAmount,
FIS.UnitPrice, FIS.DiscountAmount
FROM AdventureWorksDW2014.dbo.FactInternetSales AS FIS
INNER JOIN dbo.Customers AS C
ON FIS.CustomerKey = C.CustomerKey;
GO
Aplicar Compresión de Datos y Crear un Indice Columnstore
Aplicaremos la compresión
de datos y crearemos un índice columnstore en la tabla de hechos InternetSales.
1.
Utilice el procedimiento almacenado de sistema sp_spaceused para
calcular el espacio utilizado por la tabla InternetSales.
Utilice el siguiente código.
EXEC sys.sp_spaceused N'dbo.InternetSales', @updateusage = N'TRUE';
GO
2.
La tabla debe utilizar aproximadamente 3,080 KB para el espacio
reservado. Ahora use la sentencia ALTER TABLE para comprimir la tabla. Use la
compresión page, como se muestra en el siguiente código.
ALTER TABLE dbo.InternetSales
REBUILD WITH (DATA_COMPRESSION = PAGE);
GO
3.
Mida el espacio reservado de nuevo.
EXEC sys.sp_spaceused N'dbo.InternetSales', @updateusage = N'TRUE';
GO
4.
La tabla debería ahora utilizar aproximadamente 1,096 KB para el espacio
reservado. Puede ver que ahorró casi dos tercios del espacio mediante el uso de
la compresión Page.
5.
Crear un índice columnstore en la tabla InternetSales. Utilice el siguiente código
CREATE COLUMNSTORE INDEX CSI_InternetSales
ON dbo.InternetSales
(InternetSalesKey, CustomerDwKey, ProductKey, DateKey,
OrderQuantity, SalesAmount,
UnitPrice, DiscountAmount);
GO
6.
No tiene suficientes datos para medir realmente la ventaja del índice
columnstore y el procesamiento por lotes. Sin embargo, todavía se puede
escribir una consulta que combine las tablas y agregue los datos para que pueda
comprobar si SQL Server utiliza el índice columnstore. He aquí un ejemplo en
una consulta.
SELECT C.CountryRegion, P.CategoryName, D.CalendarYear,
SUM(I.SalesAmount) AS Sales
FROM dbo.InternetSales AS I
INNER JOIN dbo.Customers AS C
ON I.CustomerDwKey = C.CustomerDwKey
INNER JOIN dbo.Products AS P
ON I.ProductKey = p.ProductKey
INNER JOIN dbo.Dates AS d
ON I.DateKey = D.DateKey
GROUP BY C.CountryRegion, P.CategoryName, D.CalendarYear
ORDER BY C.CountryRegion, P.CategoryName, D.CalendarYear;
GO
7.
Revise el plan de ejecución y encuentre si el índice columnstore ha sido
utilizado. (Para una prueba real, debe utilizar conjuntos de datos mucho más
grandes).
8.
Es interesante medir cuánto espacio ocupa un índice columnstore. Utilice
el procedimiento de sistema sp_spaceused de nuevo.
EXEC sys.sp_spaceused N'dbo.InternetSales', @updateusage = N'TRUE';
GO
9.
Esta vez el espacio reservado debe ser aproximadamente 1,560 KB. Puede
ver que a pesar de que utilizó la compresión page para la tabla, la tabla esta
aún comprimida menos que el índice columnstore. En este caso, el índice
columnstore ocupa aproximadamente la mitad del espacio de la tabla.















